forecasts - 예측¶
- 주어진 데이터의 미래 시점 데이터를 예측합니다.
목차¶
- 설명
- 데이터 탐색
- forecasts 를 위한 데이터 전처리
- 실행 결과
- 결과 해석
설명¶
입력으로 받는 dataframe 의 데이터에 대해 미래 시점 데이터를 예측합니다.
이 때 예측하는 데이터의 기간은 옵션으로 변경 가능합니다.
적용되는 알고리즘은 linear(선형회귀알고리즘)과 ARIMA 를 적용한 seasonal 이 있습니다.
linear 알고리즘¶
... | forecasts index target [alg=linear] [f_coeff=0]
linear regression 으로 예측을 수행 합니다.
| 이름 | 설명 | 필수/옵션 |
|---|---|---|
| index | 시계열 데이터의 time 필드 입니다. | 필수 |
| target | 예측하고자 하는 target 필드 입니다. | 필수 |
| alg | 시계열 데이터 예측에 사용되는 알고리즘. default 로 linear 알고리즘. | 옵션 |
| f_coeff | 예측값이 계산되어 결과로 나오는 기간을 구하는 데 사용되는 계수. default = 0 으로 입력 데이터의 기간의 1/2 를 예측합니다. 원하는 기간이 있다면 단위 기간의 개수를 입력합니다. 예) f_coeff = 12 이고, 입력데이터 시간 단위가 1분이면 입력값의 시간 이후 +12분의 시간을 예측합니다. |
옵션 |
seasonal 알고리즘¶
... | forecasts index target alg=seasonal [f_coeff=10] [deviation=1]
계절성과 시간적 변화에 따라 예측을 수행 합니다.
내부적으로 ARIMA 알고리즘이 적용되며, AIC(Akaike’s Information Criterion) 값을 최소화 하는 order 를 구해서 모델링합니다.
| 이름 | 설명 | 필수/옵션 |
|---|---|---|
| index | 시계열 데이터의 time 필드 입니다. | 필수 |
| target | 예측하고자 하는 target 필드 입니다. | 필수 |
| alg | seasonal 은 alg=seasonal로 명시합니다. | 옵션 |
| seasonality | default 는 hourly입니다. 09:15, 10:15 처럼 같은 분(minute)에 주기성이 있는 경우입니다. 만약 daily 는 매일 5:00 동일한 시각에 비슷한 패턴이 있는 경우이고 weekly 는 이번주 화요일은 지난주 화요일과 동일한 패턴일 때입니다. |
옵션 |
| f_coeff | 예측값이 계산되어 결과로 나오는 기간을 구하는 데 사용되는 계수. default = 0 으로 입력 데이터의 기간의 1/2 를 예측합니다. 원하는 기간이 있다면 단위 기간의 개수를 입력합니다. 예) f_coeff = 12 이고, 입력데이터 시간 단위가 1분이면 입력값의 시간 이후 +12분의 시간을 예측합니다. |
옵션 |
| deviation | 예측된 값의 신뢰구간의 범위 계수입니다. | 옵션 |
데이터 탐색¶
데이터 전처리¶
SYSLOG 는 로그데이터 이므로 forecasts로 예측을 하기 위해 단위 시간(10분, 1시간 등) 의 집계 데이터를 먼저 생성해야 합니다.
그리고 예측하고 싶은 구체적인 조건을 입력합니다.
여기서는 HOST = platform2 의 10분 통계 SYSLOG COUNT 를 예측하고자 합니다.
검색명령어 창에서 10분 집계 데이터를 생성하는 명령어를 입력합니다.
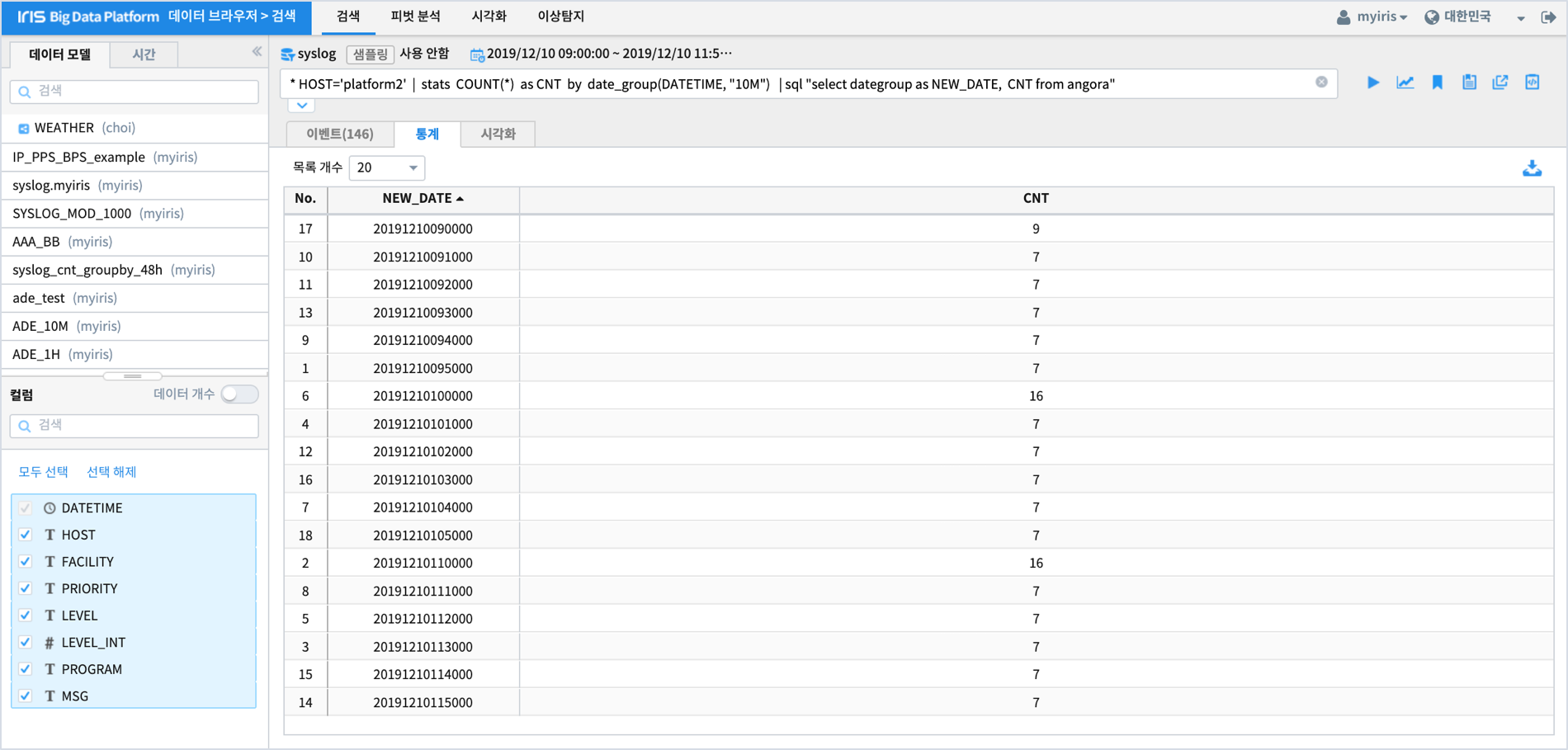
* HOST='platform2' | stats COUNT(*) as CNT by date_group(DATETIME, "10M")
| sort +dategroup
| sql "select dategroup as NEW_DATE, CNT from angora"
stats 명령어 구문이 검색명령어에 포함되면 결과는 통계탭에 출력됩니다.
SYSLOG 가 없는 시간(10분단위)은 값을 0 으로 채워야 합니다.
이 때 사용되는 명령어는 fill_zero 입니다.
fill_zero freq=600 stime=20191210090000 etime=20191210115959 time_column=NEW_DATE value=CNT
freq : 집계 시간 단위. 초. freq=600 은 600초.
stime : 집계시작시간
etime : 집계종료시간
time_column : 시간 컬럼
group_key : group 컬럼.
검색명령어 사용 예
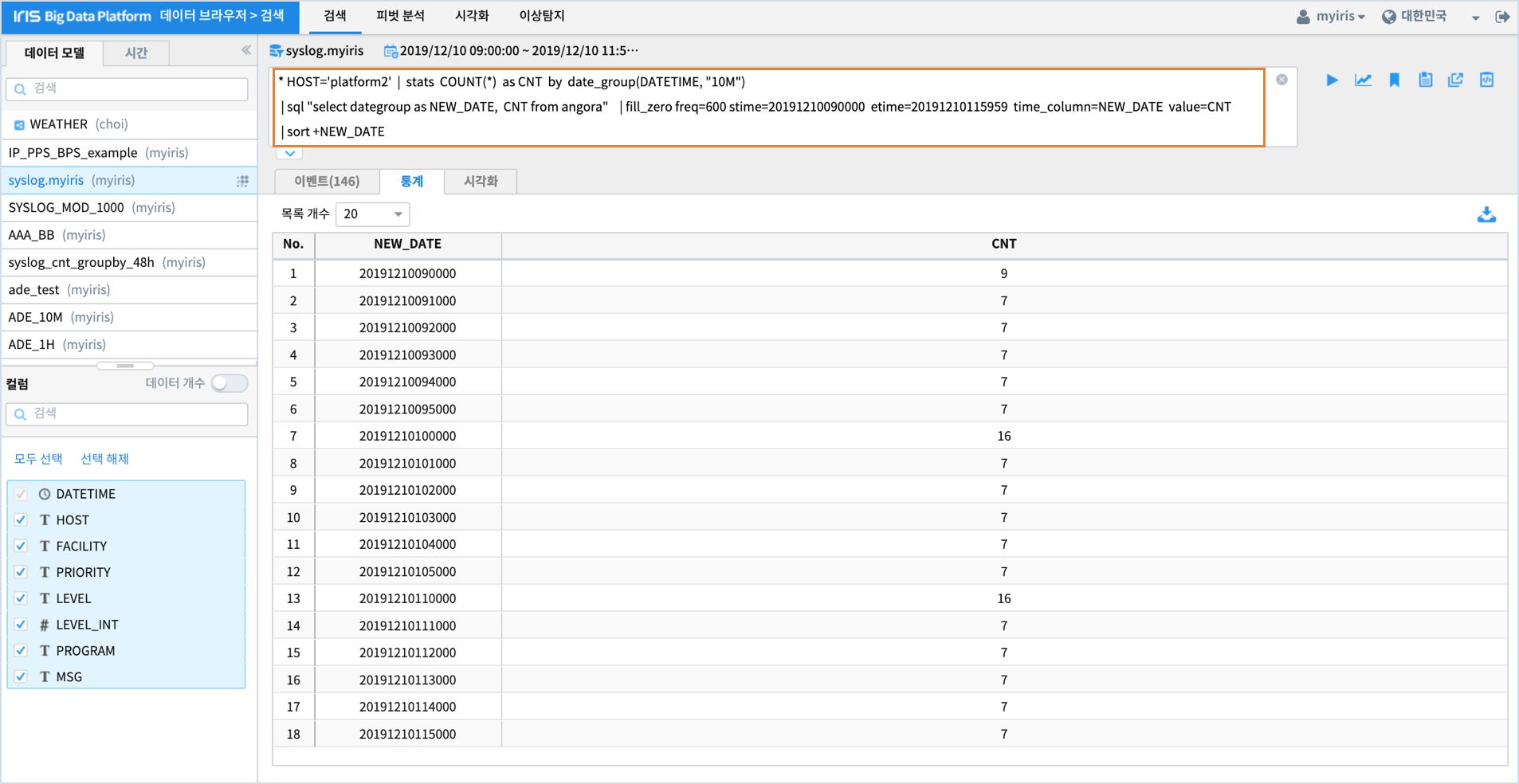
* HOST='platform2' | stats COUNT(*) as CNT by date_group(DATETIME, "10M")
| sort +dategroup
| sql "select dategroup as NEW_DATE, CNT from angora"
| fill_zero freq=600 stime=20191210090000 etime=20191210115959 time_column=NEW_DATE value=CNT
실행 결과¶
linear ( 선형회귀 알고리즘)¶
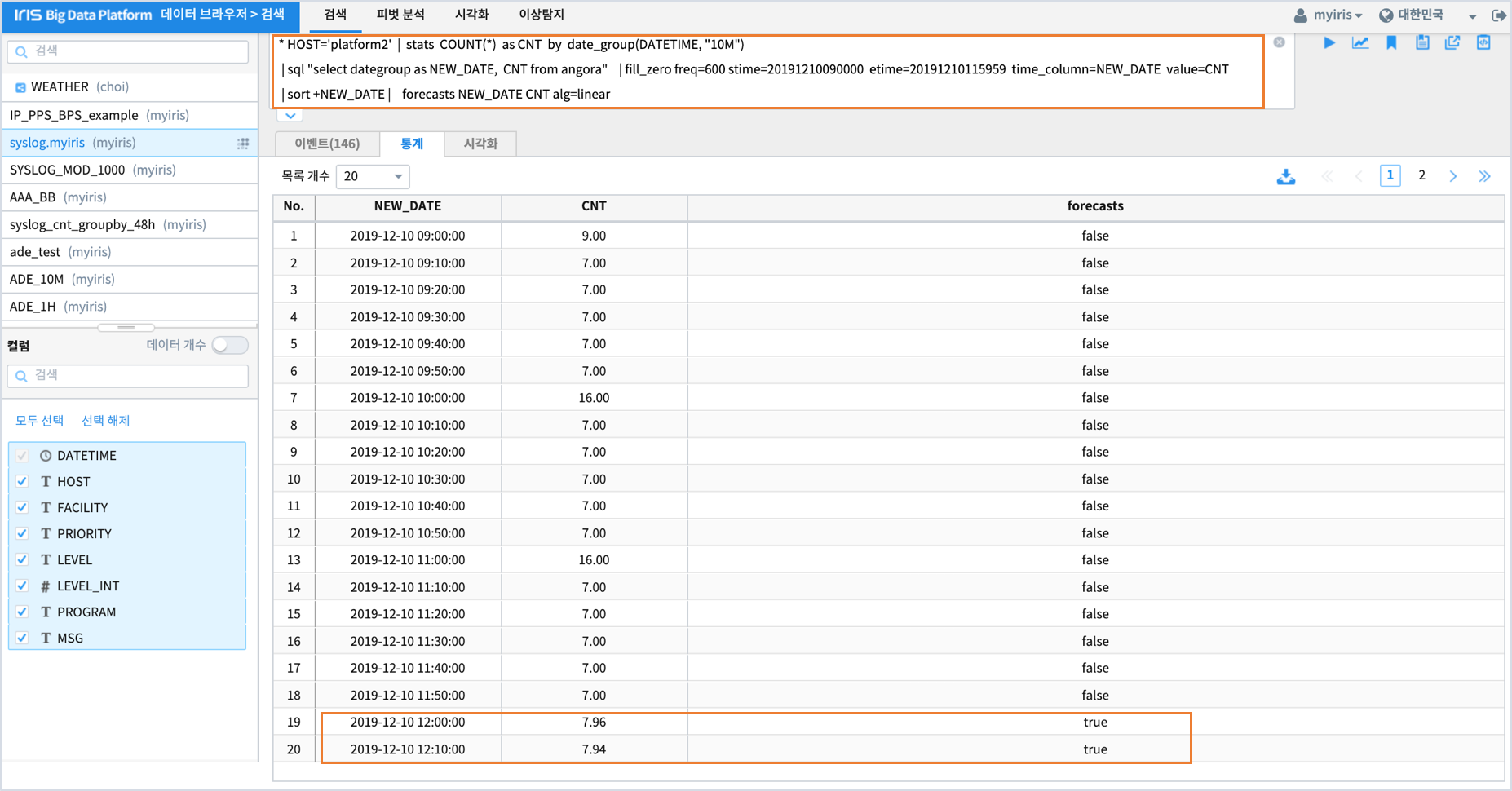
검색 메뉴에서 forecasts 실행 하기
명령어 구문
* HOST='platform2' | stats COUNT(*) as CNT by date_group(DATETIME, "10M")
| sql "select dategroup as NEW_DATE, CNT from angora"
| fill_zero freq=600 stime=20191210090000 etime=20191210115959 time_column=NEW_DATE value=CNT
| sort +NEW_DATE
| forecasts NEW_DATE CNT alg=linear
실행 결과는 stats 구문의 사용으로 통계탭에 출력됩니다.
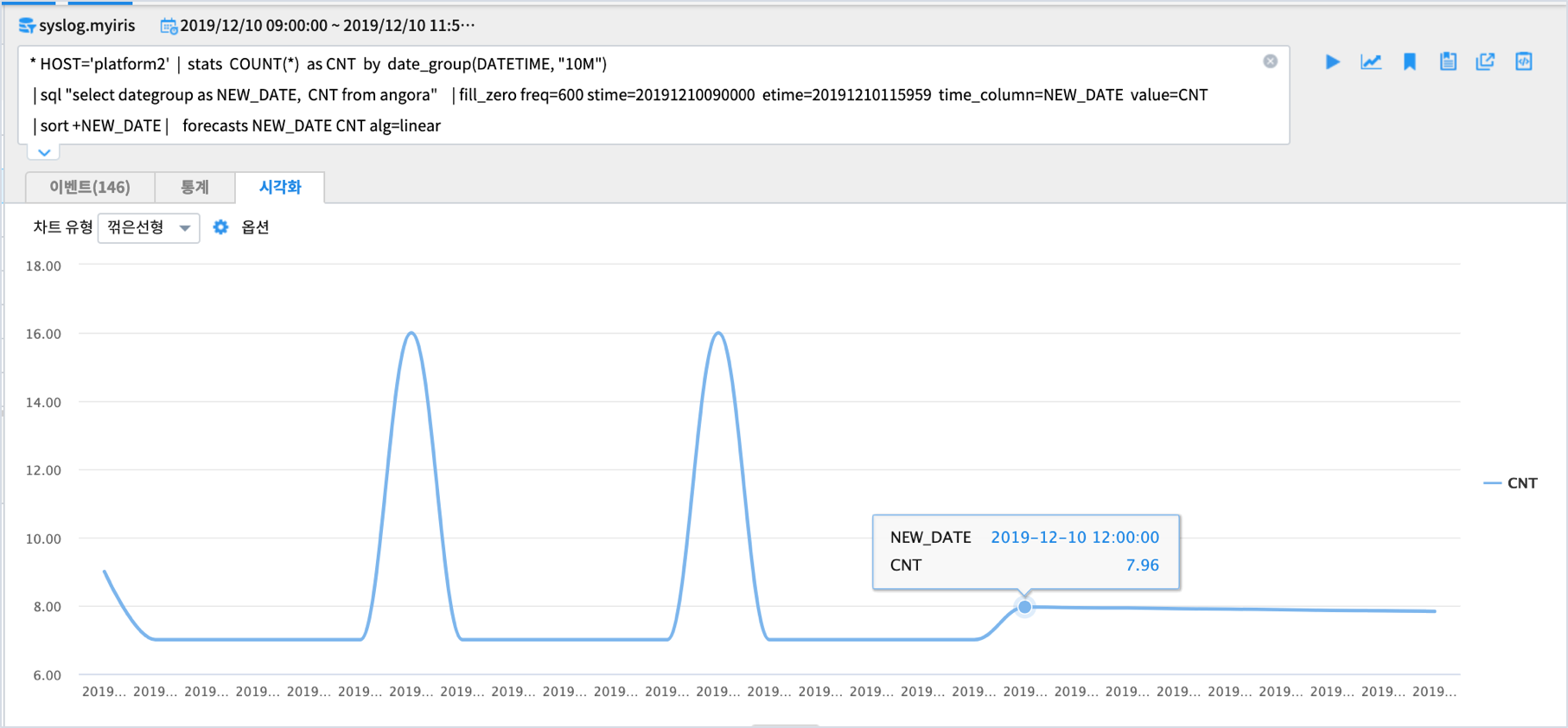
단순한 라인 챠트를 시각화 탭에서 확인 할 수 있습니다.
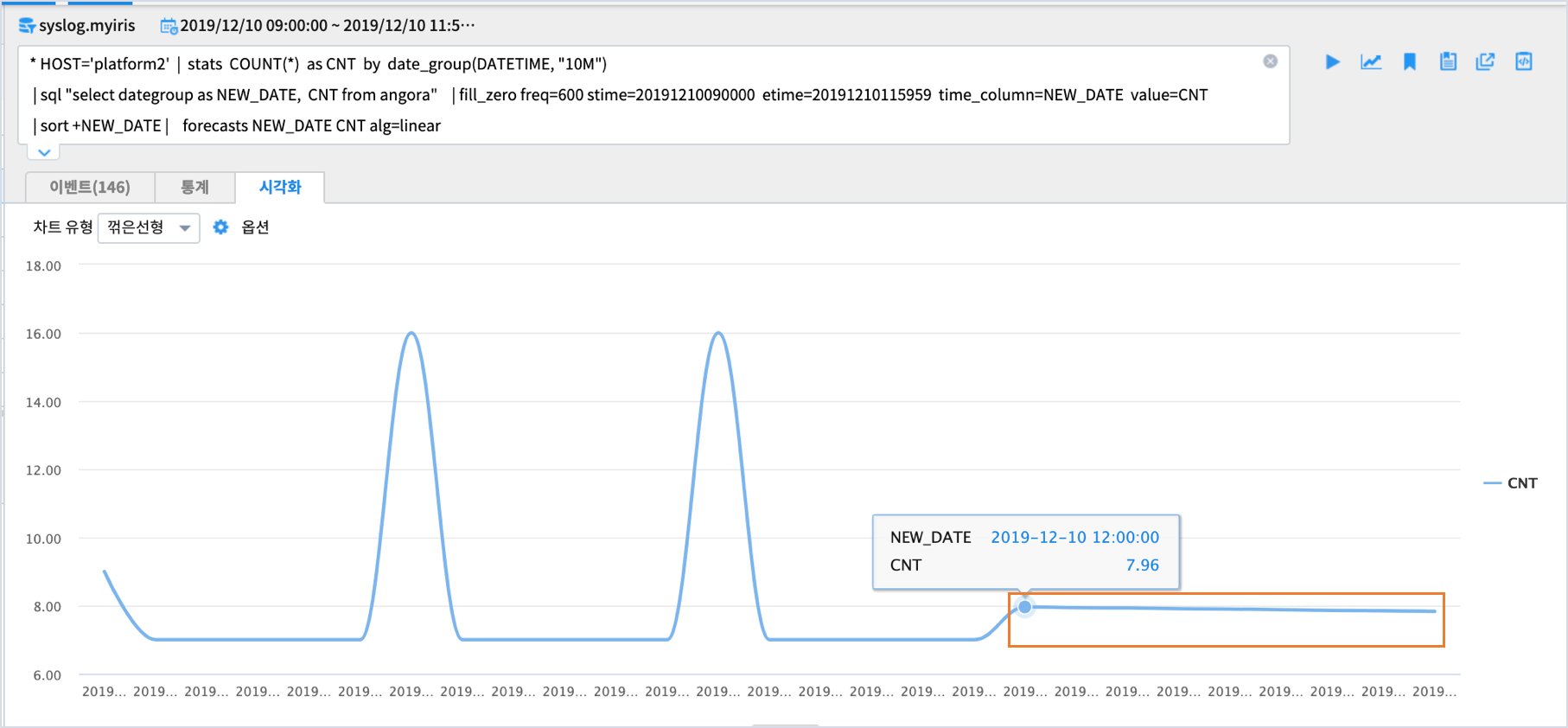
결과 해석¶
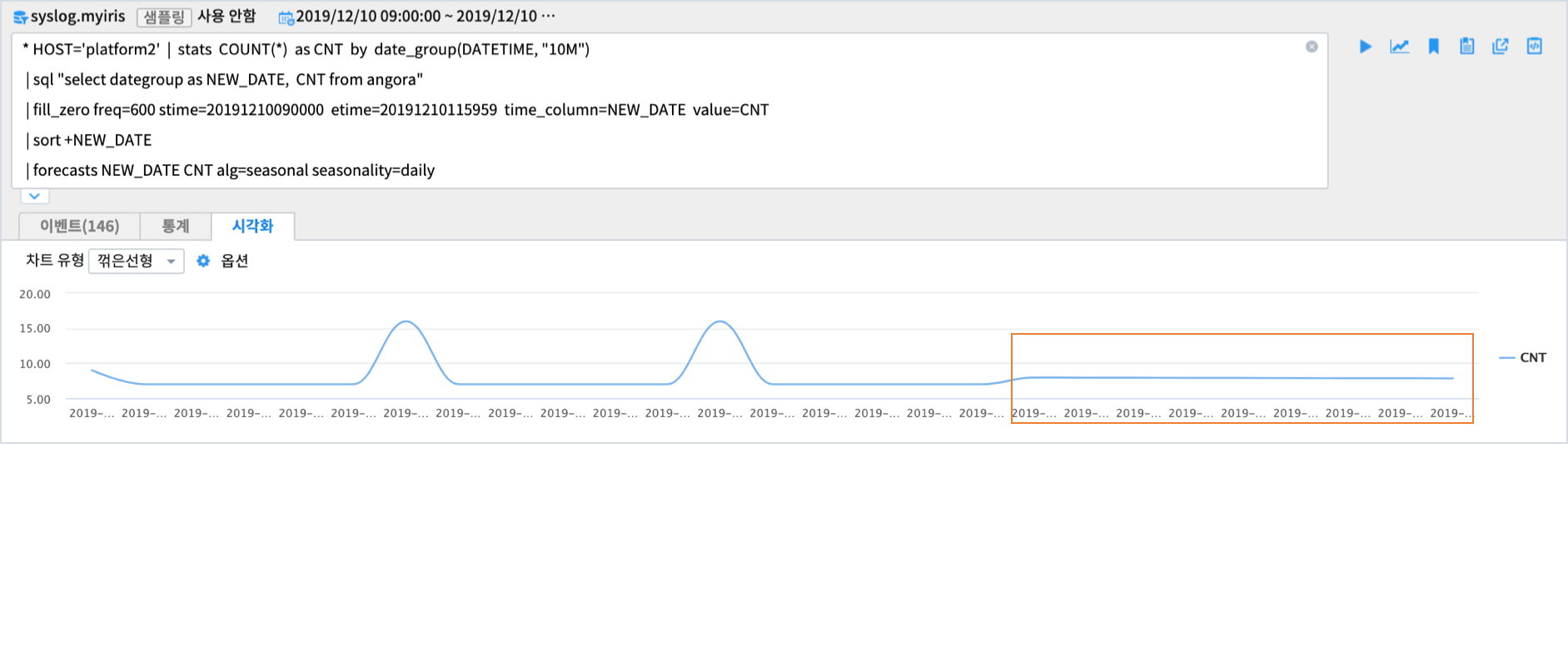
linear 알고리즘은 선형회귀법으로 예측값을 계산합니다.
주로 주기성이 없이 추세만 있는 데이터의 예측에 사용됩니다.
예측값은 기울기를 가지는 직선으로 표현되며,
해당 데이터처럼 주기가 있는 경우에는 linear 가 아닌 seasonal 옵션으로 예측을 진행하는 것이 더 타당해 보입니다.
seasonal 알고리즘¶
* HOST='platform2' | stats COUNT(*) as CNT by date_group(DATETIME, "10M")
| sql "select dategroup as NEW_DATE, CNT from angora"
| fill_zero freq=600 stime=20191210090000 etime=20191210115959 time_column=NEW_DATE value=CNT
| sort +NEW_DATE
| forecasts NEW_DATE CNT alg=seasonal seasonality=daily