데이터의 기초 통계 분석 (stats 명령어)
IRIS Analyzer >> 검색 메뉴에서 지원하는 Command 중 stats 를 이용하여 데이터의 기초 통계 분석을 진행하는 방법에 대한 설명입니다.stats 에서 제공하는 통계 함수
Arguments |
Description |
UseCase |
ETC |
|---|---|---|---|
|
평균 값을 구합니다. |
avg(컬럼명) |
|
|
카운트를 구합니다. |
count(컬럼명) |
모든 Type 가능 |
|
유니크한 개별 값의 개수를 구합니다 |
countDistinct(컬럼명) |
모든 Type 가능 |
|
가장 큰 값을 구합니다 |
max(컬럼명) |
|
|
중간 값을 구합니다. |
median(컬럼명) |
|
|
제일 작은 값을 구합니다. |
min(컬럼명) |
|
|
표본표준편차 값을 구합니다. |
stddev(컬럼명) |
|
|
표본표준편차 값을 구합니다. |
stddev_samp(컬럼명) |
|
|
모표준편차 값을 구합니다. |
stddev_pop(컬럼명) |
|
|
전체의 합을 구합니다. |
sum(컬럼명) |
|
|
표본분산 값을 구합니다. |
variance(컬럼명) |
|
|
표본분산 값을 구합니다. |
var_samp(컬럼명) |
|
|
모분산 값을 구합니다. (SQL 의 VAR_POP와 동일). |
var_pop(컬럼명) |
|
|
사분위수 범위(IQR = Q3 - Q1) |
iqr(컬럼명) |
|
|
지정한 percentage 를 이용하여 각 분위별 값을 구합니다. |br| percentage 는 정수로 입력하며 0 < percentage < 100 까지 입력이 가능합니다. |
quantile(컬럼명, 10) |br| quantile(컬럼명, 25) |
|
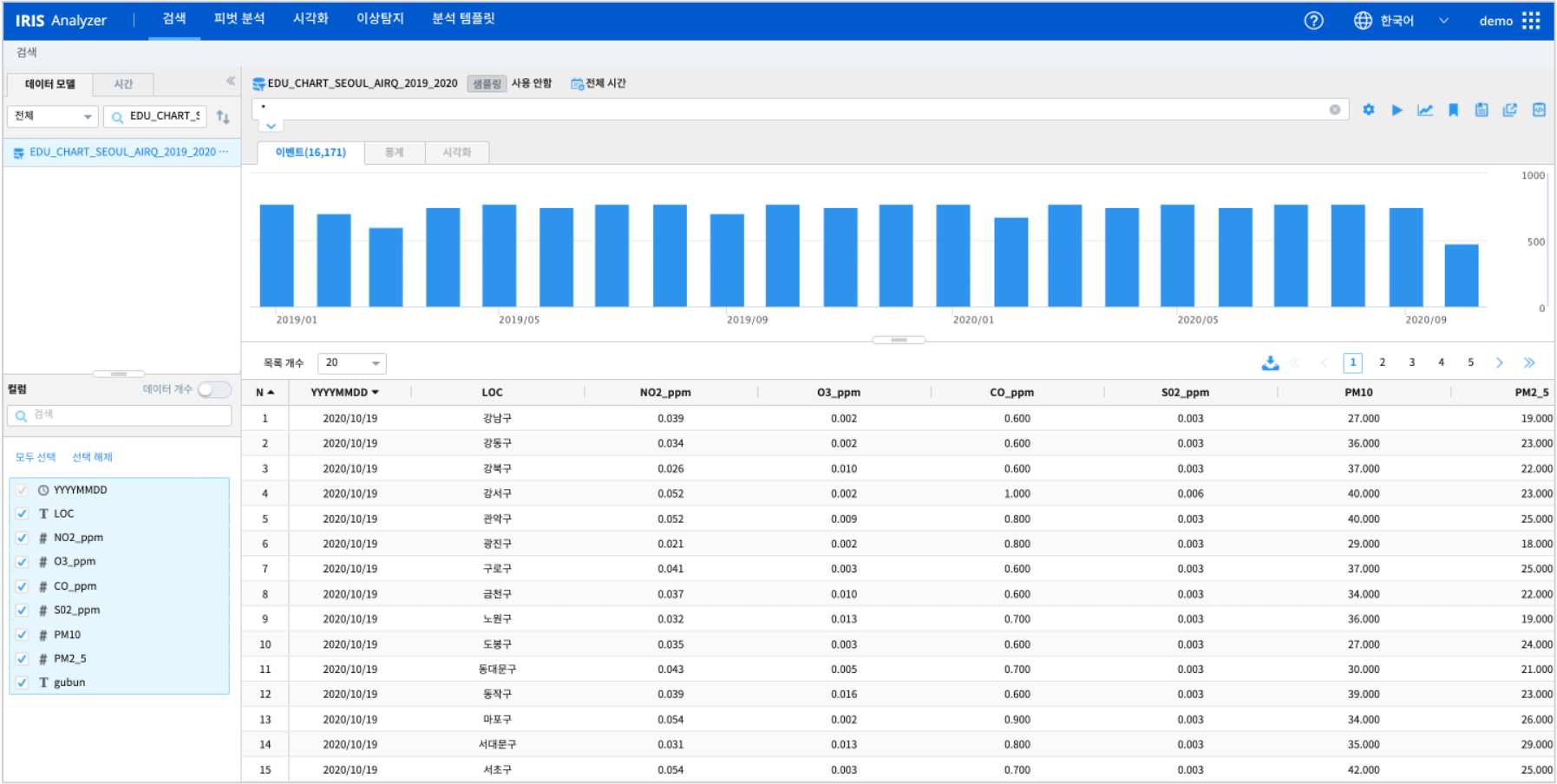
예제 데이터 모델
기초 통계 산출
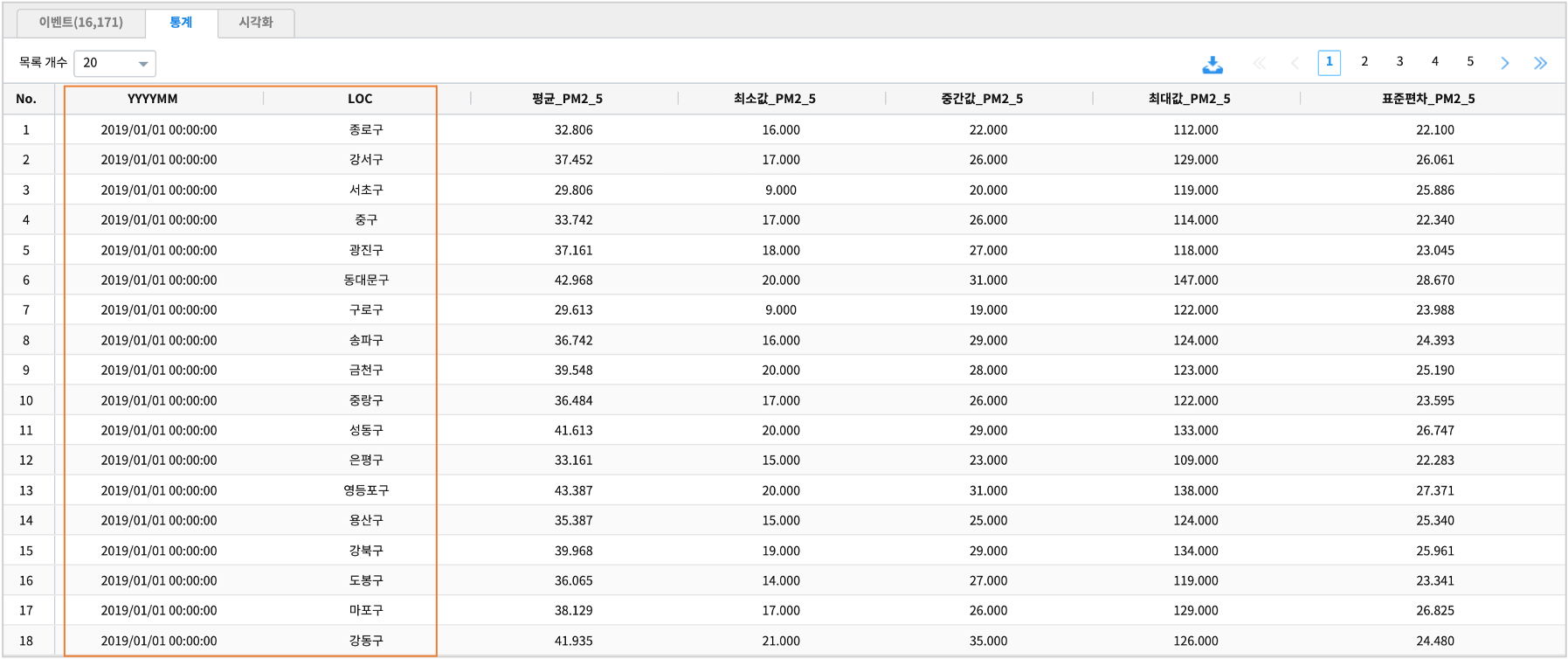
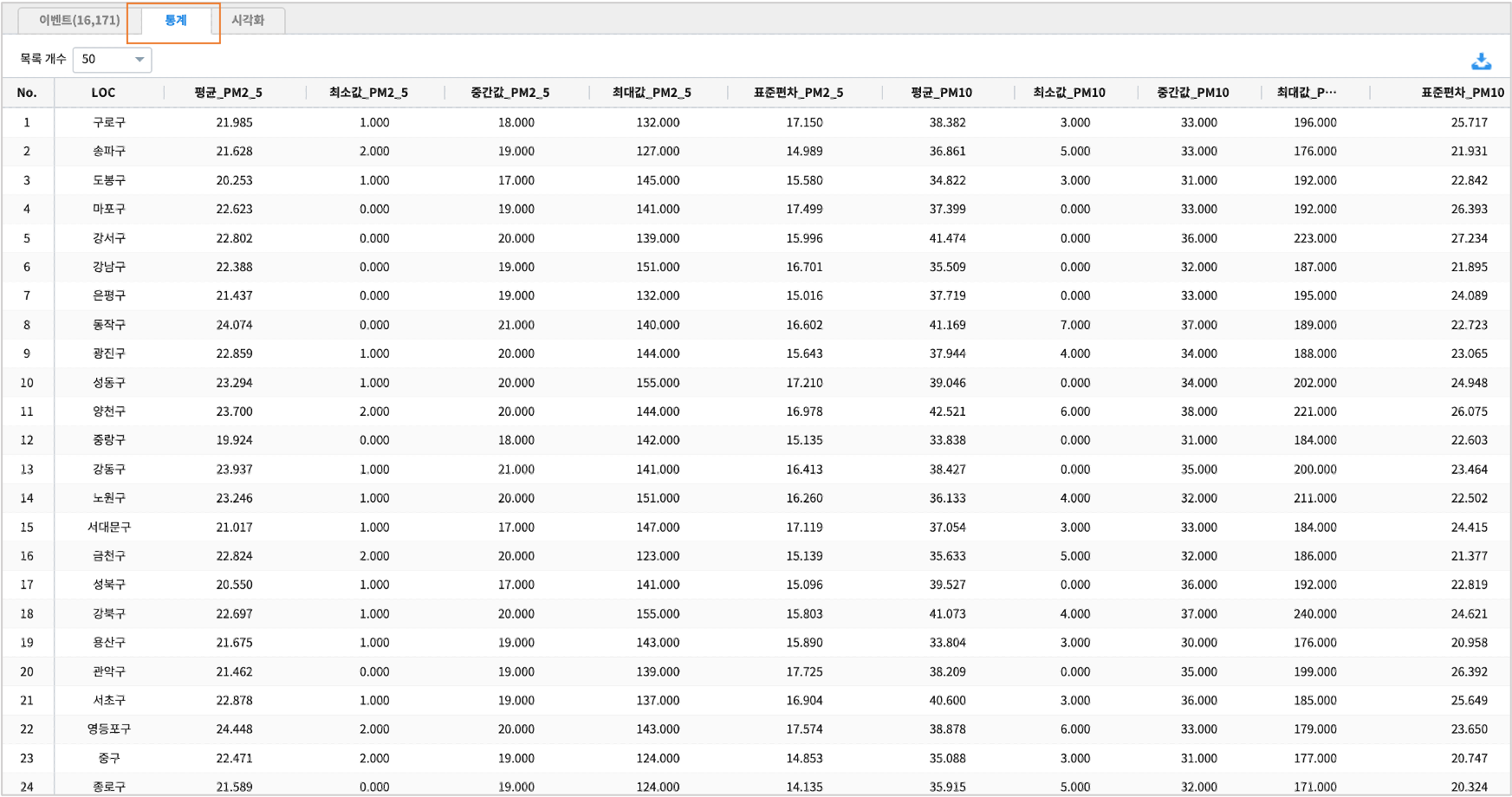
LOC(측정지점)별 통계
TEXT형 변수인 LOC(측정지점)을 기준으로PM2_5(초미세먼지농도)의 평균, 최댓값, 중간값, 최솟값, (표본)표준편차
PM10(미세먼지농도)평균, 평균, 최댓값, 중간값, 최솟값, (표본)표준편차
* | stats avg(PM2_5) as 평균_PM2_5,
min(PM2_5) as 최소값_PM2_5,
median(PM2_5) as 중간값_PM2_5,
max(PM2_5) as 최대값_PM2_5,
stddev(PM2_5) as 표준편차_PM2_5,
avg(PM10) as 평균_PM10,
min(PM10) as 최소값_PM10,
median(PM10) as 중간값_PM10,
max(PM10) as 최대값_PM10,
stddev(PM10) as 표준편차_PM10 by LOC
stats 명령어의 실행결과는 통계 탭에 출력됩니다.
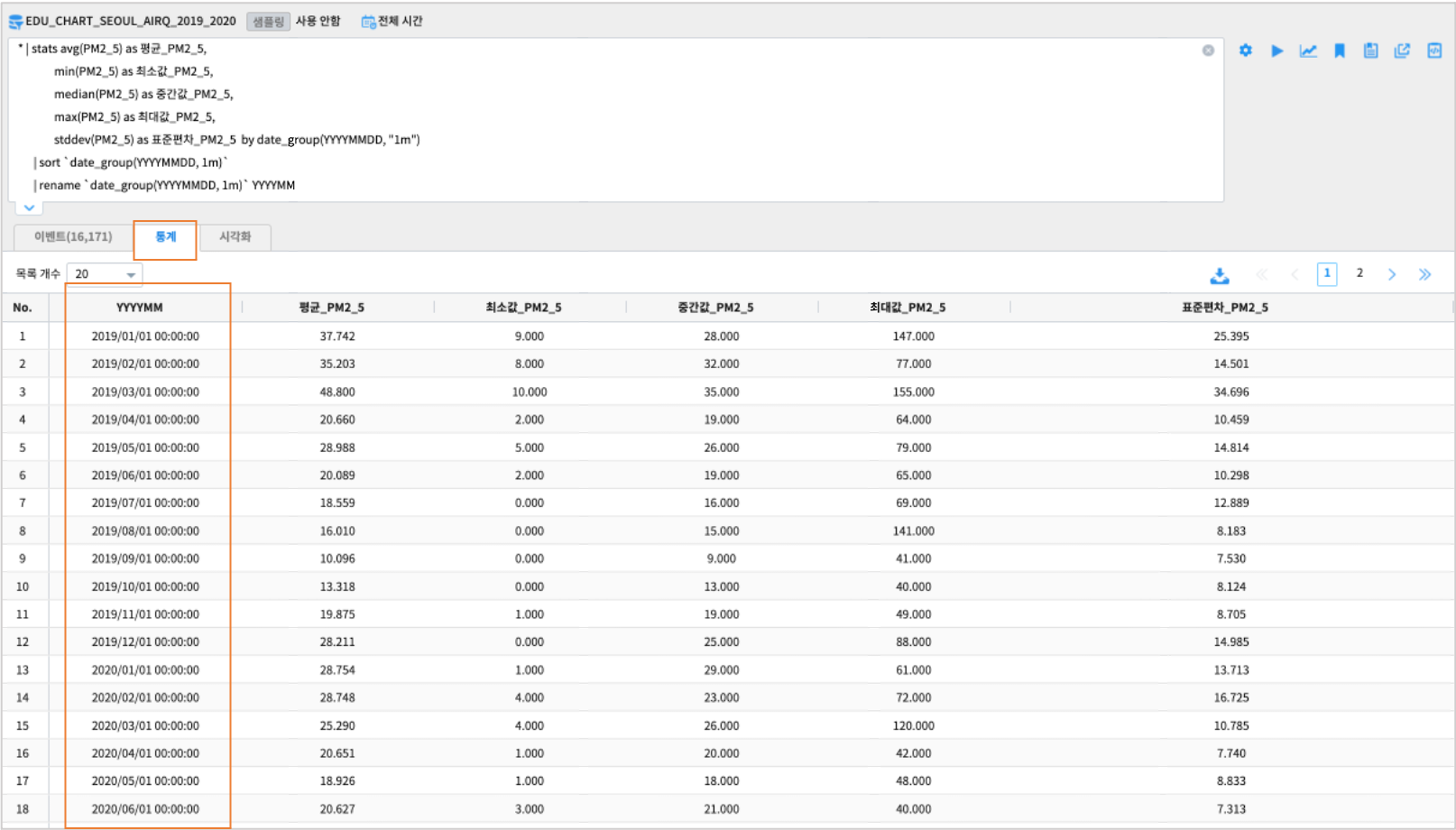
YYYYMMDD(날짜)별 통계
date 타입 변수입니다.date_group 으로 원하는 단위 시간으로 변경하여 by 구문에 사용합니다.date_group 함수를 이용합니다.검색어
* | stats avg(PM2_5) as 평균_PM2_5,
min(PM2_5) as 최소값_PM2_5,
median(PM2_5) as 중간값_PM2_5,
max(PM2_5) as 최대값_PM2_5,
stddev(PM2_5) as 표준편차_PM2_5 by date_group(YYYYMMDD, "1m")
| sort `date_group(YYYYMMDD, 1m)`
| rename `date_group(YYYYMMDD, 1m)` YYYYMM
결과
날짜형 변수를 처리하는 함수
date_group의 사용법은 다음과 같습니다.
형식: date_group(컬럼명, 단위)
단위 |
의미 |
예시 |
|---|---|---|
y |
년 |
1년 : date_group(컬럼명, “1y”) |
m |
월 |
1개월 : date_group(컬럼명, “1m”) |
d |
일 |
1일 : date_group(컬럼명, “1d”) |
H |
시간 |
1시간 : date_group(컬럼명, “1H”) |
M |
분 |
1분 : date_group(컬럼명, “1M”) |
S |
초 |
10초 : date_group(컬럼명, “10S”) |
기준 변수가 2개 이상일 때
, 로 구분하여 나열합니다.검색어
* | stats avg(PM2_5) as 평균_PM2_5,
min(PM2_5) as 최소값_PM2_5,
median(PM2_5) as 중간값_PM2_5,
max(PM2_5) as 최대값_PM2_5,
stddev(PM2_5) as 표준편차_PM2_5 by date_group(YYYYMMDD, "1m"), LOC
| sort `date_group(YYYYMMDD, 1m)`
| rename `date_group(YYYYMMDD, 1m)` YYYYMM
결과