stats
개요
각종 통계 데이터를 구하는 명령어 입니다.
타입
TEXT, INTEGER, BIGINT, REAL, DATE, TIMESTAMP
설명
BY 절 없이 쓰인다면, 전체 결과를 aggregation을 하여, 하나의 열만 검색 결과로 출력 될 것입니다.BY 절에 의하여 그룹핑할 field가 주어진다면, 해당 field의 유니크한 값들의 개수 만큼의 열이 검색 결과로 출력 될 것 입니다.Parameters
... | stats FUNCTION (AS ALIAS_NAME)?(, FUNCTION (AS ALIAS_NAME)?)* (BY FIELD_NAME (, FIELD_NAME)*)?
이름 |
설명 |
필수/옵션 |
|---|---|---|
|
|
필수 |
|
|
옵션 |
|
그룹핑 할 필드명을 지정 가능합니다. 추가로 date_group 함수 사용가능 date_group 옵션은 아래 테이블에서 확인할 수 있습니다. |
옵션 |
aggregation functions list
Arguments |
Description |
UseCase |
ETC |
|---|---|---|---|
|
평균 값을 구합니다. |
avg(컬럼명) |
|
|
카운트를 구합니다. |
count(컬럼명) |
모든 Type 가능 |
|
유니크한 개별 값의 개수를 구합니다 |
countDistinct(컬럼명) |
모든 Type 가능 |
|
가장 큰 값을 구합니다 |
max(컬럼명) |
|
|
중간 값을 구합니다. |
median(컬럼명) |
|
|
제일 작은 값을 구합니다. |
min(컬럼명) |
|
|
표본표준편차 값을 구합니다. |
stddev(컬럼명) |
|
|
표본표준편차 값을 구합니다. |
stddev_samp(컬럼명) |
|
|
모표준편차 값을 구합니다. |
stddev_pop(컬럼명) |
|
|
전체의 합을 구합니다. |
sum(컬럼명) |
|
|
표본분산 값을 구합니다. |
variance(컬럼명) |
|
|
표본분산 값을 구합니다. |
var_samp(컬럼명) |
|
|
모분산 값을 구합니다. (SQL 의 VAR_POP와 동일). |
var_pop(컬럼명) |
|
|
사분위수 범위(IQR = Q3 - Q1) |
iqr(컬럼명) |
|
|
지정한 percentage 를 이용하여 각 분위별 값을 구합니다. |
quantile(컬럼명, 10) |
|
date_group unit(option) list
unit |
설명 |
|---|---|
10y |
10년 |
1y |
1년 |
10m |
10월 |
1m |
1월 |
10d |
10일 |
1d |
1일 |
10H |
10시간 |
1H |
1시간 |
10M |
10분 |
1M |
1분 |
10S |
10초 |
1S |
1초 |
Examples
예제 데이터
sepal_length |
sepal_width |
speceis |
|---|---|---|
5.1 |
3.5 |
Iris-setosa |
4.9 |
3.0 |
Iris-setosa |
4.7 |
3.2 |
Iris-setosa |
3.7 |
4.7 |
Iris-setosa |
5.8 |
8.2 |
Iris-setosa |
7.3 |
2.6 |
Iris-setosa |
7.4 |
5.4 |
Iris-setosa |
6.5 |
7.8 |
setosa |
6.2 |
4.7 |
setosa |
5.9 |
12.5 |
setosa |
4.3 |
5.2 |
setosa |
5.7 |
7.3 |
setosa |
5.2 |
3.8 |
setosa |
2.5 |
7.1 |
setosa |
- avg, stddev_samp, stddev_pop, min, max, median, sum, var
species이라는 필드 이름으로 그룹핑 된 결과 에서 개수,sepal_width필드의 평균, 표준편차, 최소값, 최대값, 중간값, 합계, 분산을 구합니다.
* | stats count(*) as 개수,
avg(sepal_width) as 평균_sepal_width,
stddev_samp(sepal_width) as 표본표준편차_sepal_width,
stddev_pop(sepal_width) as 모표준편차_sepal_width,
min(sepal_width) as 최소값_sepal_width,
max(sepal_width) as 최대값_sepal_width ,
median(sepal_width) as 중간값_epal_width,
sum(sepal_width) as 합계_sepal_width,
var(sepal_width) as 분산_sepal_width
by species | sort species
species |
개수 |
평균_sepal_width |
표본표준편차_sepal_width |
모표준편차_sepal_width |
최소값_sepal_width |
최대값_sepal_width |
중간값_epal_width |
합계_sepal_width |
분산_sepal_width |
|---|---|---|---|---|---|---|---|---|---|
Iris-setosa |
7 |
4.371428571428572 |
1.9567952419830796 |
1.8116403661672287 |
2.6 |
8.2 |
3.5 |
30.6 |
3.829047619047619 |
setosa |
7 |
6.914285714285714 |
2.8783262332060113 |
2.6648122804047416 |
3.8 |
12.5 |
7.1 |
48.4 |
8.284761904761906 |
참고 : var_samp /stddev_samp / stddev_pop 계산
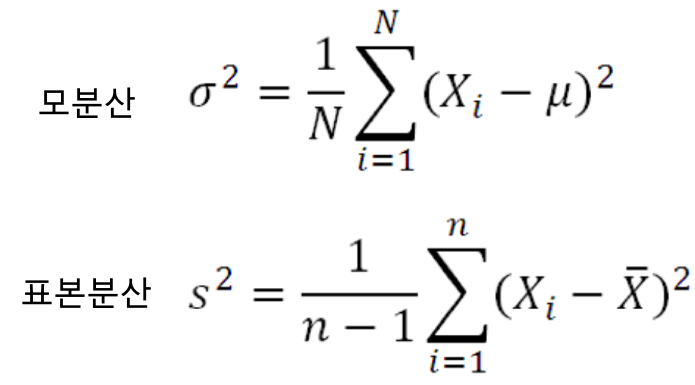
* | stats countDistinct(species) as 종의개수
종의개수 |
|---|
2 |
iqr: interquartile range = Q3 - Q1
* species='setosa' | fields sepal_Width, species | sort sepal_Width | stats iqr(sepal_width) by species
=> 7개 데이터를 작은 값부터 큰 값까지 sorting 한 후 7 * 0.25 에 해당하는 1사분위수는 2번째 값 = 4.7
7 * 0.5 에 해당하는 2사분위수는 중간값으로 4번째 값 = 7.1
7 * 0.75 에 해당하는 3사분위수는 6번째 값 = 7.8
IQR = 3사분위수 - 1사분위수 = 7.8 - 4.7 = 3.1
* | stats iqr(sepal_width) as IQR_sepal_width by species
species |
IQR_sepal_width |
|---|---|
setosa |
3.1 |
예제 데이터 2
DATETIME |
HOST |
|---|---|
“2020-07-03 12:14:00” |
gcs1 |
“2020-07-03 12:24:00” |
gcs1 |
“2020-07-05 12:34:00” |
gcs1 |
“2020-07-03 11:34:00” |
gcs1 |
“2020-07-04 04:34:00” |
gcs1 |
“2020-07-03 04:34:00” |
gcs2 |
“2020-07-04 02:34:00” |
gcs2 |
“2020-07-03 01:34:00” |
gcs2 |
“2020-07-04 05:34:00” |
gcs2 |
“2020-07-05 03:34:00” |
gcs2 |
“2020-07-04 12:13:00” |
gcs2 |
“2020-07-03 12:14:00” |
gcs2 |
HOST 별로 1 단위로 로그 COUNT 를 구합니다.일
* | stats count(*) as CNT by date_group(DATETIME, "1d"), HOST
date_group(DATETIME, 1d) |
HOST |
CNT |
|---|---|---|
2020-07-04 |
gcs1 |
1 |
2020-07-03 |
gcs2 |
3 |
2020-07-05 |
gcs1 |
1 |
2020-07-05 |
gcs2 |
1 |
2020-07-04 |
gcs2 |
3 |
2020-07-03 |
gcs1 |
3 |
백쿼터(back-quote : `` ` `` ) 를 사용하여 단어가 아닌 필드명도 사용할 수 있습니다.
* | stats count(*) as `개수(HOST)` by date_group(DATETIME, "1d"), HOST | sort dategroup